Database Storage Structures
Use of xml in refrigeration bds to store complex structures
Alexander Svidenkov
The database is usually not self-reliant, is part of the information system. Irrespective of the number of links in the system, the interface with the user is located on the other side of the OBD end, and the programmer ' s task is to provide a simple and understandable way of working with OBD data and facilities. With all its coherence and visibility, the classic way of storing and presenting the facilities of the developed entity has some of the disadvantages encountered by any developer who has attempted to implement such a system with sufficient complexity.Let's see a pretty standard situation. In the system, account must be taken of buyers, all of their requisitions, and naturally, the possibility of looking and editing them. In the classical version, we need to:
- Create a plate.
CUSTOMERS
CUST_ID integer PK,
NAME varchar (200),
OKONH varchar(20),
OKPO varchar(20),
BIK varchar(20),
COUNTRY varchar(50),
CITY varchar(50),
♪ ♪ ♪
- Create a form of editing with Label and DBEdit elements, tie them to the relevant fields of DataSet, and implement the usual processing knob buttons, delete, change.
So far, it seems simple. Except that single-type forms in the programme are rabbits, why many do not survive, and create their language to describe such forms, for their dynamic creation.
 Complications arise if:
Complications arise if:
- We want to keep records not only of legal persons, but also of individuals who need additional attributes that become meaningless to the lawns (and vice versa).
- There was a need to add a new attribute in the system ' s work. The same chain is the field to the table, the shape changes, the new structure of the OBD metadata, the new programme.
- Some attributes are not known in advance. For example, the organization may have one phone, 2, 3..10.
- The system is replicated, and attribution kits vary dramatically in different settings.
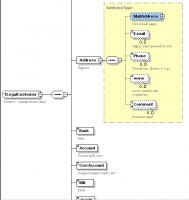
In some situations, these problems are solved by the storage of an XML version of the facility with a corresponding XSD scheme. In this case, we:
- CUSTOMERS (CUST_ID integer PK, NAME varchar (200), XML BLOB )
- In XSD, we define the type we need.
- The annex calls for a universal editing form to be transmitted by type XSD of the scheme and XML of the card.
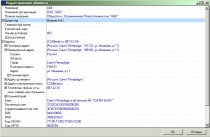
In the example, the XML version of Object Inspector is used as a editing element.
It was based on TZPropList from Genadie Zuev, which is free and with reference. In the same way, any Object Inpector can be refined - at the entrance, he receives a reference to two XML knots - XSD schema and a self-revision object. If the object is empty, it is based on XSD. The result is on the pictures. Additional bonuses are auto-completion and listing lists for listed types, formats and masks for other types.
What are the benefits of this scheme:- Even at an early stage, it is less labour-intensive than standard, and it describes the object in one place, both the types and size of the fields and their names, titles and comments.
- A description of the structure of the facilities is fully stored in the OBD system, the annex may not know.
- The format descriptions in XSD schemes are much richer than the set of types server data♪